Introductie AI & ontwerp & UX
Deze post is een uitwerking van een interne, informele presentatie van het AI werkgroepje van de vakgroep Ontwerp en UX van de gemeente Amsterdam. Ik (Jurian Baas) heb deze 17 juni 2024 gegeven. Het is bedoeld als een introductie en startpunt voor verdere verdiepende lezingen en workshops over het onderwerp. Er kunnen fouten inzitten, en is zeker onvolledig. Laat het ons weten als je op- of aanmerkingen hebt!
Het onderwerp AI kreeg veel stemmen tijdens de bepaling van de werkgroepen van de vakgroep. Veel van jullie hebben waarschijnlijk het idee ‘dat we hier iets mee moeten’. Vooral door de snelle opkomst van ChatGPT en andere taalmodellen.
Inmiddels is de ergste hype wel een beetje voorbij. Voorspellingen als ‘binnen een jaar bestaat beroep X niet meer’, zijn niet uitgekomen. Maar het is ook wel duidelijk dat deze technologie een blijvertje is, en waarschijnlijk wel veel in het leven en werk van mensen gaat veranderen.
En dat betekent waarschijnlijk veel voor ons als vakgroep! De kans is groot dat we generatieve AI in ons werk gaan gebruiken, doordat het in tools gaat zitten waar we mee werken. Maar belangrijker nog: het gaat wat betekenen voor de levens van de mensen waar we dingen voor ontwerpen. En wie weet kunnen we zelf ook op een ethische manier bijdragen aan het ontwikkelen van toepassingen met AI.
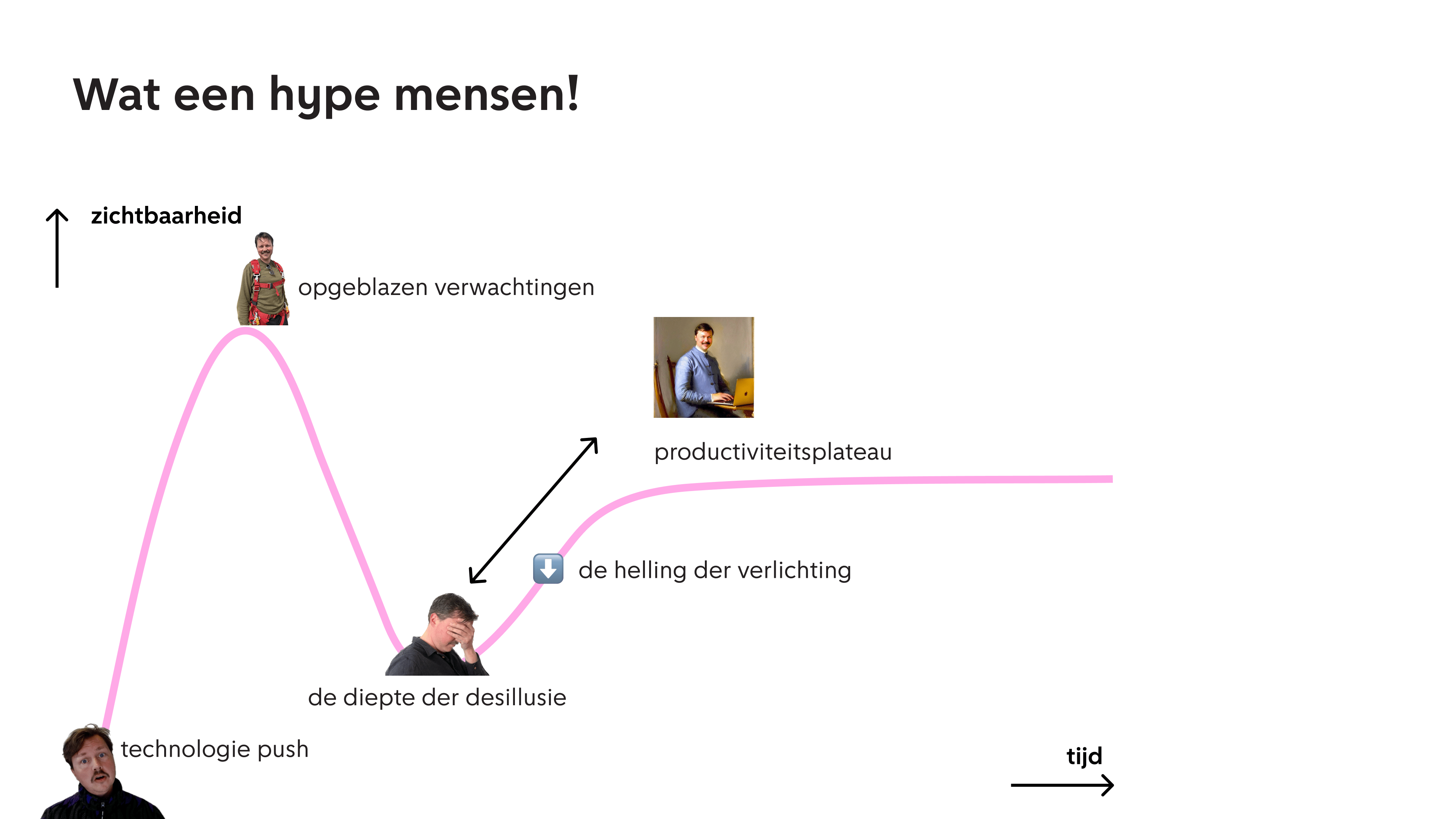
Ik heb wel aardig lopen stoeien met mijn plek in de hype cycle, in het algemeen wat technologische veranderingen en wat machine learning betreft, maar al helemaal over generatieve AI.
Ik was eerst echt compleet omver geblazen toen de eerste plaatjesmodellen uitkwamen, vooral omdat ik die ook op mijn eigen computer kon draaien en ze kon finetunen op mijn eigen hoofd, dat van mijn vriendin en wijlen kat. Ik dacht echt dat volledig gepersonaliseerde disney films aanstaande waren, maar ook dat je binnenkort niks meer kon geloven van wat je zag. Het bracht hele interessante discussies op met artiesten en filosofen over wat ‘maken’ en creativiteit nu eigenlijk inhoudt. Het bleek een beetje waar, en ook weer niet.
Het gaf me het gevoel dat het leuke, chaotische internet op een bepaalde manier weer was aangebroken. Heel spannende technologie, beetje magisch, die uitingskracht in handen van veel meer mensen kan geven, die de gevestigde orde kan doen schudden. Een game changer, machtsveranderaar.
Helaas is het grote bedrijven gelukt om de potentie van dat internet om te zetten in grote machtsuitoefening, en heeft die vrije expressie een gecontroleerd of soms juist gevaarlijk karakter gekregen.
Bij taalmodellen als chat zag ik een veel minder choatische maar potentieel grotere ontwikkeling voor me, waar mensen allemaal een soort onvermoeibare, slimme maar ook wel saaie werkbutler zou krijgen. Maar de ideeën die ik er mee uitwerkte waren het steeds net niet. Steeds hadden ze enorme belofte in zich, maar ook heel veel saaiheid, fouten, en fantasieloosheid. Na best wel lang proberen werd ik daar echt een beetje moedeloos van. Ik gebruik taal en schrijven om mezelf uit te drukken, nog meer dan dingen visueel maken gek genoeg in deze groep, en nu was er iets dat daar een enorme impact op kan hebben maar tegelijk zo saai is.
Ik vond het ook te moeilijk om mijn probeersels te rijmen met de vele ethische bezwaren die er zijn, en het krachtenveld van multinationals is ook helemaal niet gezellig.
Maar nu de modellen weer beter en zuiniger zijn geworden, de verwachtingen realistischer zijn, en de ontwikkeling van open source taalmodellen heel hard gaat, ben ik wel weer gepast enthousiast. Ik denk dat mits goed gebruikt deze techniek heel veel kan betekenen voor ons werk, en ons kan helpen om op een vrijere, grondiger manier na te denken over vraagstukken en sommige saaie dingen echt makkelijker kan maken.

We willen met het AI groepje van de vakgroep de volgende 2 hoofdvragen uitzoeken:
Hoe moeten we ons tot AI moeten verhouden als ontwerper? Het maakt veel los en veranderd veel in de maatschappij, dus laten we goed proberen te snappen hoe het werkt en welke toepassingen er mee mogelijk zijn.
Hier spelen vervolgvragen als: welke rol/plek gaat AI krijgen in het dagelijks leven van de mensen waar wij voor ontwerpen? Welke grote maatschappelijke verschuivingen zien we? Hoe kan de relatie overheid / burger hierdoor veranderen? Hoe houden we daar rekening mee?
Ook willen we kijken hoe we met AI kunnen en willen werken: hoe gebruiken we deze techniek op een goede manier, en voor het goede? Wat is goed ontwerp voor AI? Hoe ontwerpen we voor toepassingen waar AI inzit? Kunnen we iets leukers bedenken dan een chat interface?

Ik denk dat veel van jullie het net zo verwarrend vinden en snel vinden gaan als ik, dat hoop ik in ieder geval wel. Ik denk ook dat er een paar van jullie waarschijnlijk de boot nog even afhouden, zovan ‘we zien het wel’. Het lijkt me daarom goed om tijdens de AI meetings samen te worstelen met deze materie. Dat gaan we vooral de resterende twee sessies doen: dan hebben we een verdiepende lezing op het programma staan, wellicht met een expert. En daarna gaan we graag in een workshop met jullie ook echt aan de slag met AI.
Vandaag beginnen we met de basics. Het is best lastig om een goed gedeeld begrip te hebben van wat AI precies is, hoe het werkt, wat je er allemaal mee kan, wat de waarden achter deze technologie zijn, etc.
Er is ook veel mystiek rondom deze technologie, en veel slechte informatie. Het is goed om het allemaal een beetje over hetzelfde te hebben :)
Als groepje hebben we een eerste poging gedaan om hier achter te komen, en dat willen we vandaag graag met jullie delen. We gebruiken veel voorbeelden. We delen de presentatie met alle links zodat jullie het later nog eens kunnen checken als je dat leuk vindt.
Wat mezelf betreft: ik ben al een tijdje bovenmatig geïnteresseerd in dit onderwerp, en heb er ook al wat dingen mee geprogrammeerd. Voor mensen die graag dingen coden zijn taalmodellen echt een wild ding, vind ik. Maar voor veel andere toepassingen schiet ik een beetje heen en weer, tussen hoop en vrees, zoals ik al liet zien in de hype cycle.
Wat is AI?


Intelligentie is meteen al een best moeilijk begrip, vind ik. Het gaat over zoveel. Maar als we een veilige definitie gebruiken, kunnen we zeggen dat het het het vermogen om kennis te verzamelen, begrijpen en gebruiken is. In het engels betekent het ook informatie, meestal met een machtspositie of strategisch voordeel (als in Central Intelligence Agency). Dit vind ik voor het begrip van Artificial Intelligence wel aardig: als je het zo bekijkt kan het ook gaan over gegenereerde informatie, gegenereerde intelligence.
Maar meestal als mensen het over Artificial intelligence (AI) hebben, gaat het toch wel over het vermogen van computers om taken uit te voeren waarvoor mensen hun intelligentie inzetten. Denk aan interacteren met de omgeving, analyseren, redeneren, problemen oplossen en voorspellen.

Rond AI gonzen heel veel meningen en opvattingen. Omdat het zo’n hype is worden er veel kreten de ether ingeslingerd. Deze bevatten zeker een kern van waarheid, maar zijn denk ik bijna nooit helemaal waar.
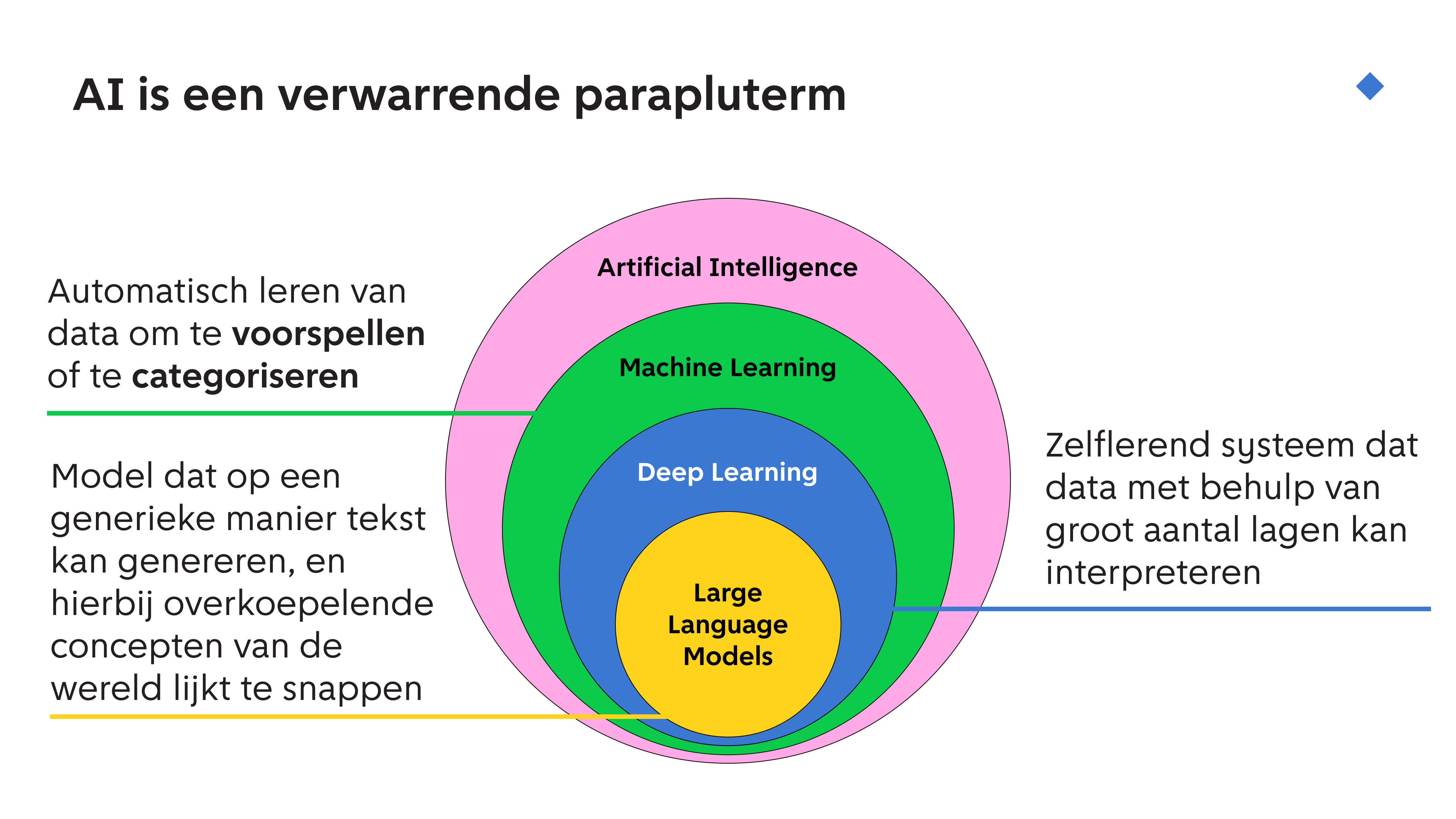
Er valt ook heel veel onder AI: het is al decennia lang een wetenschapsveld. Je kon al voor het jaar 2000 Kunstmatige Intelligentie in Groningen studeren. Maar de laatste 10-20 jaar is er vooral door het gebruik en de versnelling van videokaarten een enorme boom geweest om machine learning modellen te maken om dingen te kunnen voorspellen, of categoriseren. In plaats van een computer het werk laten doen, voer je data aan wat ingewikkelde statistiek, en laat je dat uitspraken doen. Deep learning is daarbinnen weer een manier om met een groot aantal ingewikkelde lagen data te analyseren, om verbanden te zoeken die voor mensen niet te vinden zijn, of niet logisch zijn. Denk aan verhoudingen van lijnen en kleuren in grote hoeveelheden plaatjes, of afwijkende elementen in röntgenfoto’s.


We hebben hier samen even naar het algoritmeregister gekeken.
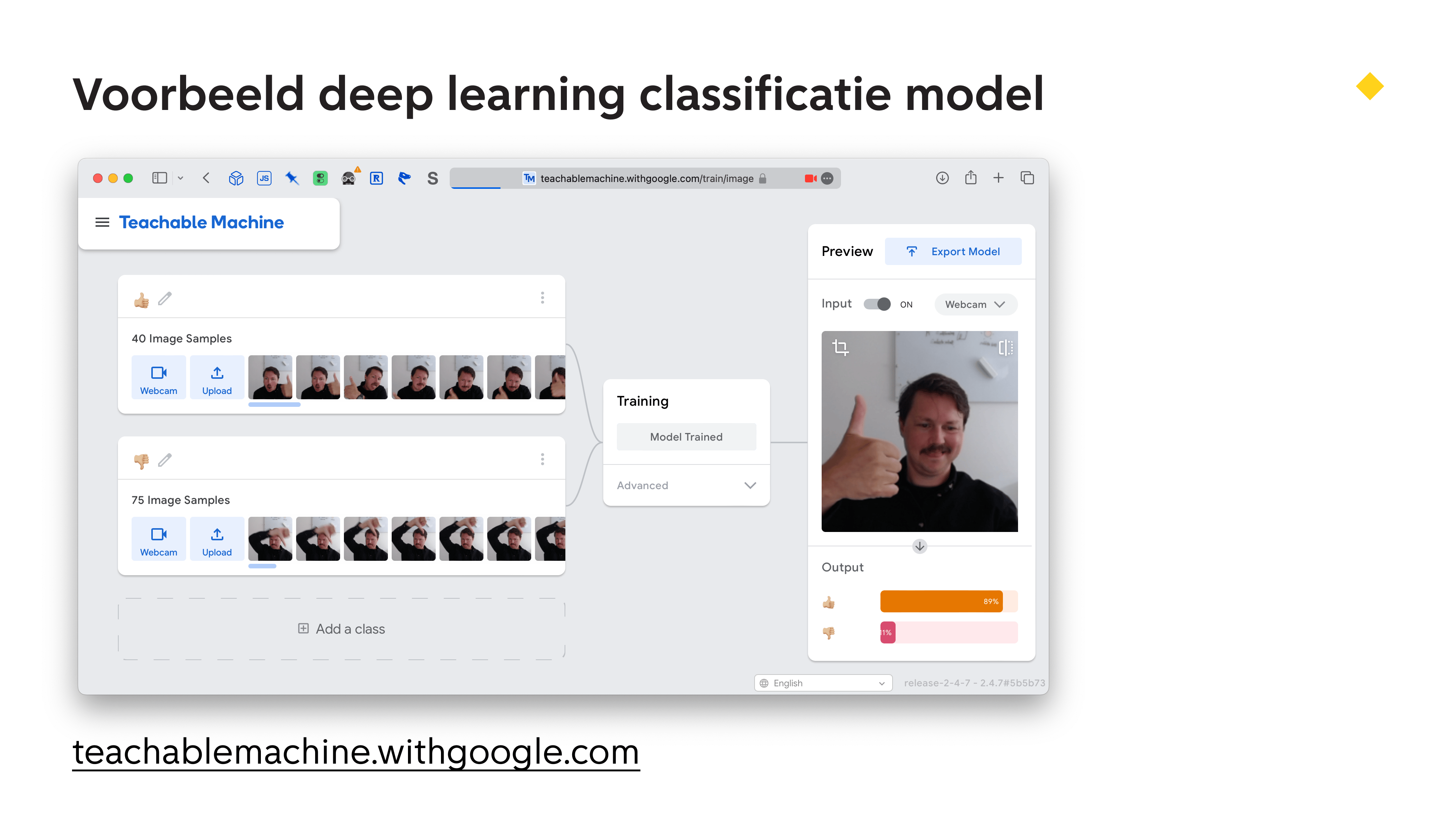
Het trainen van een simpel plaatjes classificatie model gaat tegenwoordig best makkelijk! Hier zien jullie een voorbeeld dat Google heeft gemaakt. Je kan hiermee op verschillende manieren duidelijk maken welke dingen je wil classificeren. Met plaatjes, audio en video. We doen het hier even met lichaamsposes. Ik hou mijn duim omhoog bij voorbeeld A. En naar beneden bij voorbeeld B. En ik train nu een model.
Als dat model klaar is, kan ik mijn webcam weer aanzetten en het model continu uitspraken laten doen over wat deze ziet. Als ik mijn duim omhoog doe dan ‘ziet’ hij dit, en met mijn duim omlaag ook.
Dit is natuurlijk een simpel voorbeeld, maar hiermee kan je bijvoorbeeld in een interview op het einde vragen om mensen op wat vragen hun duim omhoog of omlaag te doen, of je kan iets magisch laten gebeuren als mensen in een ruimte vragen ‘wat is dit?‘. Goed, ik neem een beetje een voorschot op het ‘wat kan je er mee’ deel dat straks nog komt.

En dan de dingen die de laatste tijd zoveel hype hebben veroorzaakt: ChatGPT en aanverwanten, plaatjesgenerators, en alle toepassingen van deze dingen in andere producten.
- Chat
- In producten zoals Notion
- Plaatjes
- Muziek
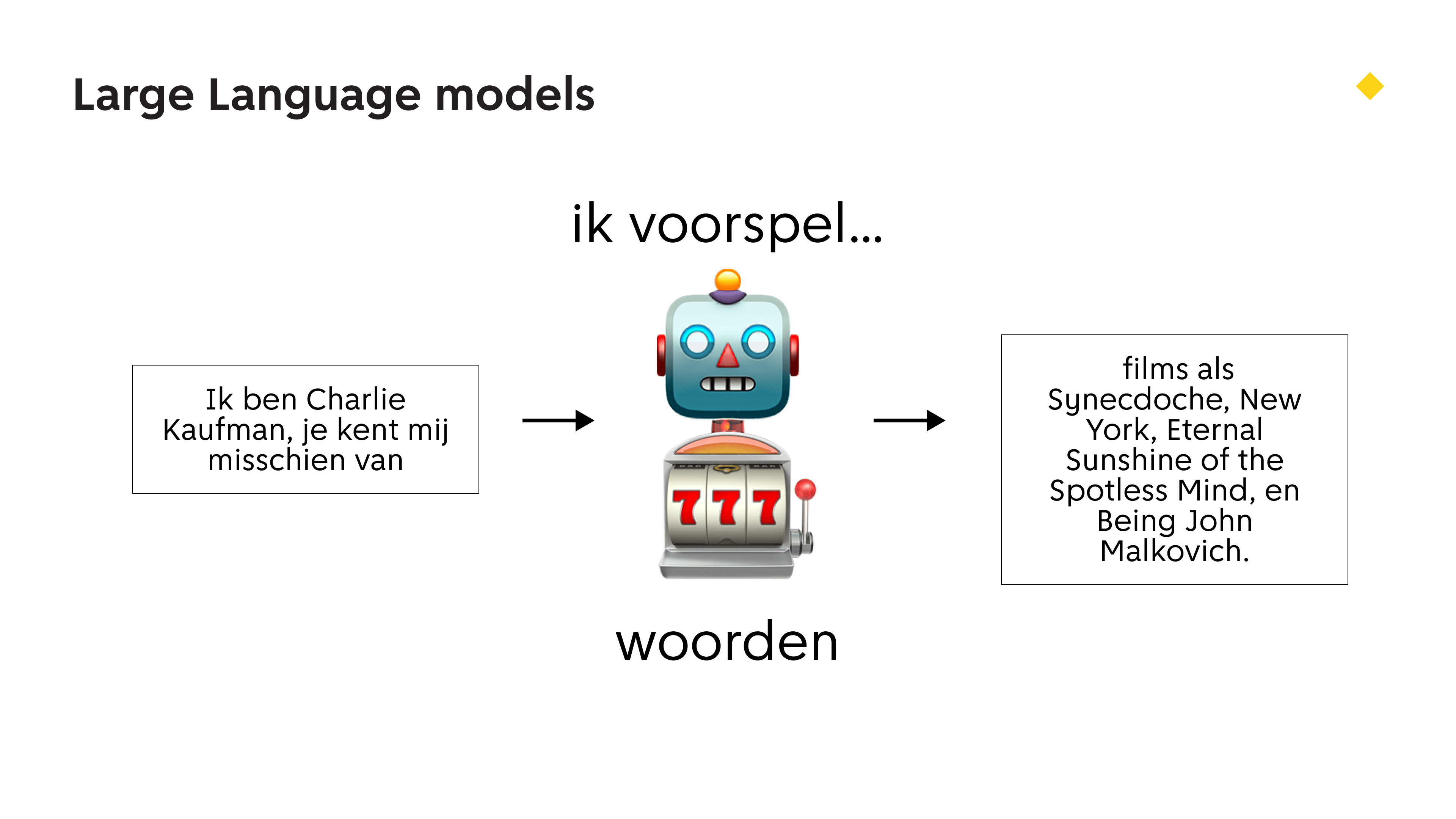
Welke dingen kan een taalmodel dan aan? Deze dingen! Woorden, plaatjes, woorden uit plaatjes, audio.
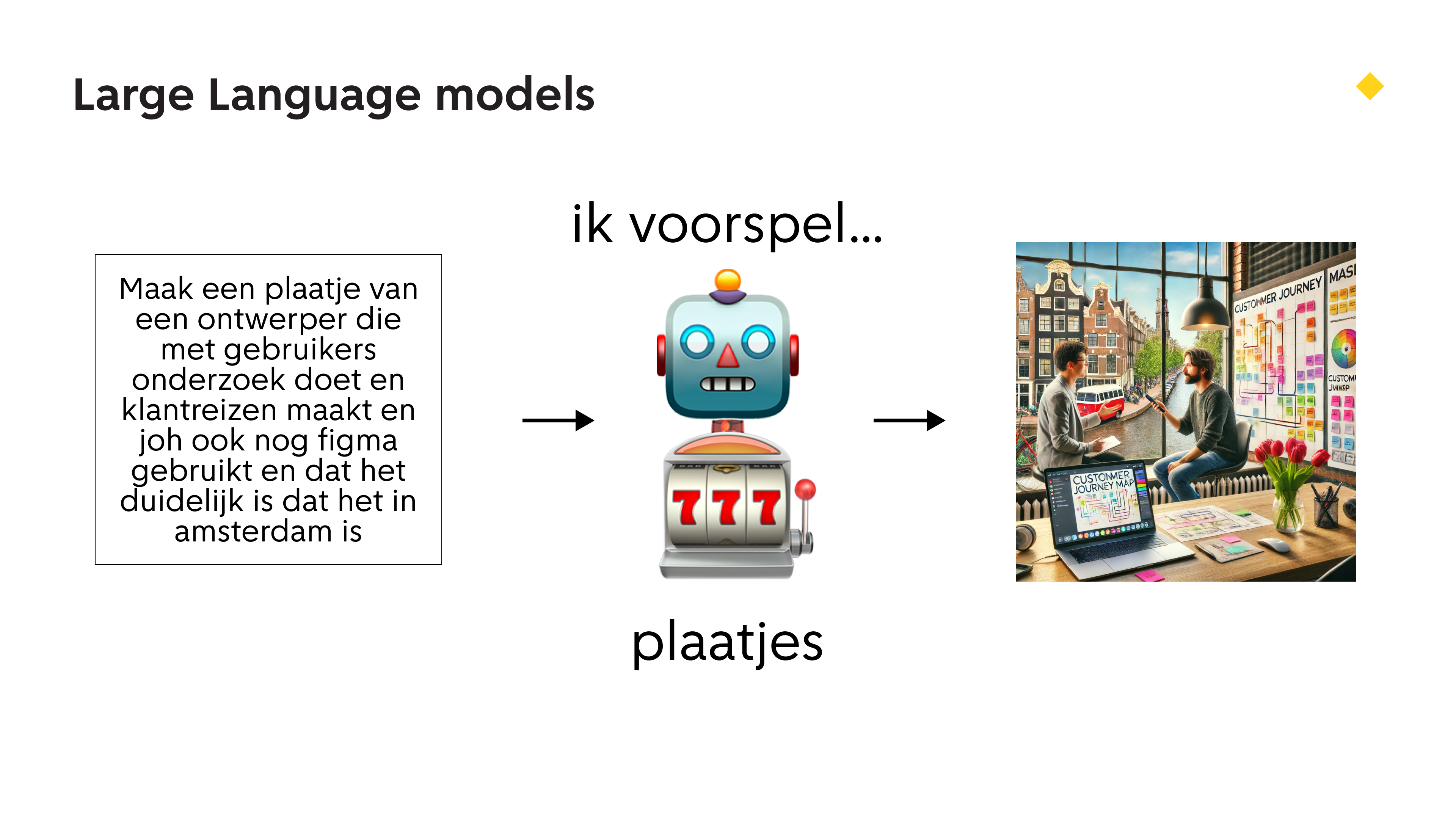
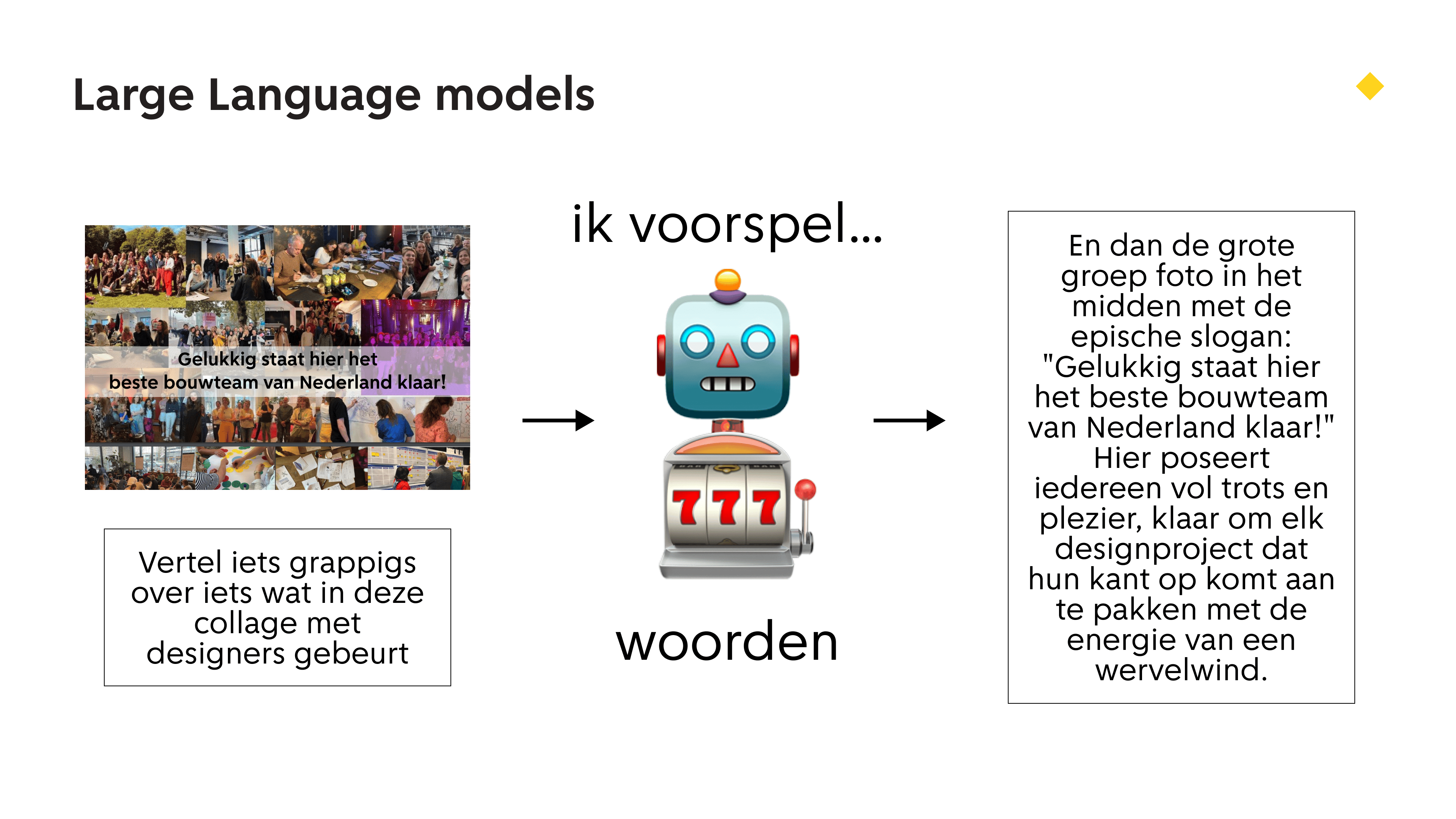
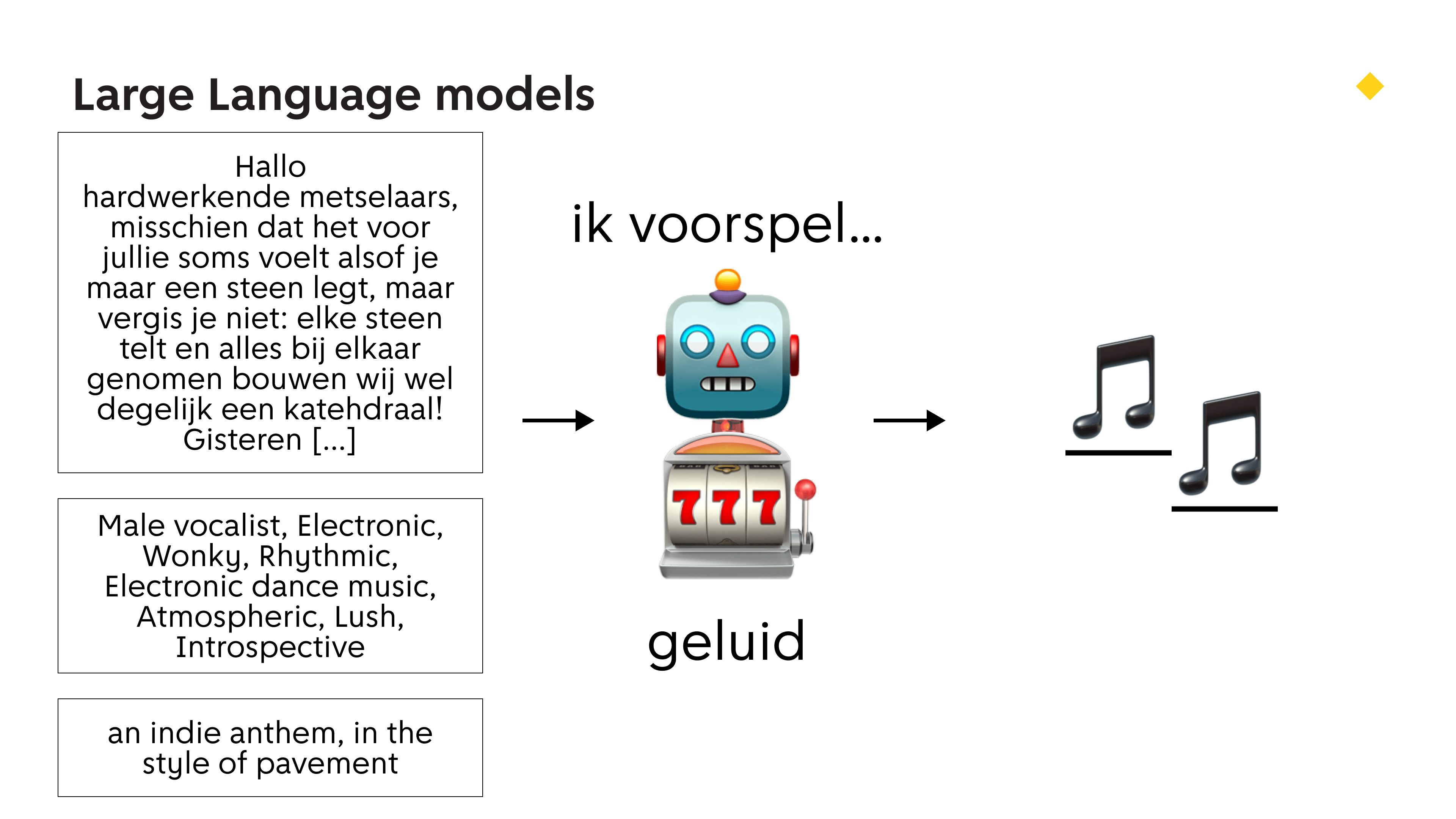
Je kan zelfs liedjes maken! Zoals deze modern classic met lyrics van Eveline:
Hoe werkt het?

Hoe deze dingen nu echt precies werken is best ingewikkelde materie. Data science is echt een vak / wetenschappelijke discipline, waar verregaande statistische en wiskundige kennis wordt gecombineerd met programmeren en een goed gevoel voor data problemen.
Toch denk ik dat het belangrijk is om op een basaal niveau te weten hoe deze toepassingen technisch werken. Het haalt namelijk een groot deel van de mysterie weg. Als je iets niet helemaal begrijpt, als je geen verklaring kan vinden voor dingen, ben je als mens snel geneigd om een mysterieus, magisch of zelfs bovennatuurlijk beeld te hebben van de veronderstelde werking. Voor mijn gevoel is dit bij AI zeker ook zo.

We gaan even naar een filmpje kijken! Het gaat express heel snel, maar ik ga erna een samenvatting geven.

Een algoritme is een set van regels en instructies die een computer geautomatiseerd volgt bij het maken van berekeningen om een probleem op te lossen of een vraag te beantwoorden.
De basis van algoritmes bij machinelearning liggen in de statistiek. De data en de taak bepaalt vaak het algoritme wat je kiest.
Bij AI toepassen programmeer je een computer niet om direct een taak uit te voeren, maar voer je data aan een algoritme dat op verschillende manieren bekijkt of ze voor jou iets kunnen voorspellen of iets kunnen classificeren.
Dit heeft zo’n vlucht genomen omdat de berekeningen op videokaarten gemaakt kunnen worden die veel sneller en goedkoper zijn geworden.

De kwaliteit van je data is dus bepalend en belangrijk! En data is net als techniek nooit neutraal, daar komen we later nog op terug. Er was een beetje een data hype in het bedrijfsleven en de gemeente, en toen dachten we even dat we alles ‘met data’ op konden lossen. Maar vaak was de data dan helemaal niet toereikend, of speelde een ander probleem dat mensen zonder technische kennis niet goed konden zien.
En wat je meet, waar je de nadruk op legt, zeg veel over hoe je tegen dingen aankijkt. Dat is geen neutrale aangelegenheid.
Simpele algoritmes werken met herkenbare features, bijvoorbeeld: ‘kunnen we aan de hand van deze eigenschappen en omstandigheden voorspellen of iemand woonfraude pleegt’.
Deep learning algoritmes bestaan uit meerdere lagen en zoeken eigenschappen in data die voor een mens moeilijk te vinden of te bevatten zijn, bijvoorbeeld in data die bestaat uit plaatjes of relaties in taal.
De uitkomst is een model: een machine die data als input neemt en een classificatie of voorspelling als output geeft
 Een large language model voorspelt op basis van input een gerelateerd symbool, zoals een woord, plaatje, audio, of video.
Een large language model voorspelt op basis van input een gerelateerd symbool, zoals een woord, plaatje, audio, of video.
Deze modellen bevatten een enorm groot en complex raamwerk aan relaties van concepten, uitingen, feiten. Dit is opgebouwd met een deep learning algoritme dat maandenlang met heel veel rekenkracht is getraind op terrabytes aan informatie op het internet.

Om me te helpen met uitleggen hoe ze ongeveer werken, gebruik ik eerst twee plaatjes uit een explainer van the Guardian.
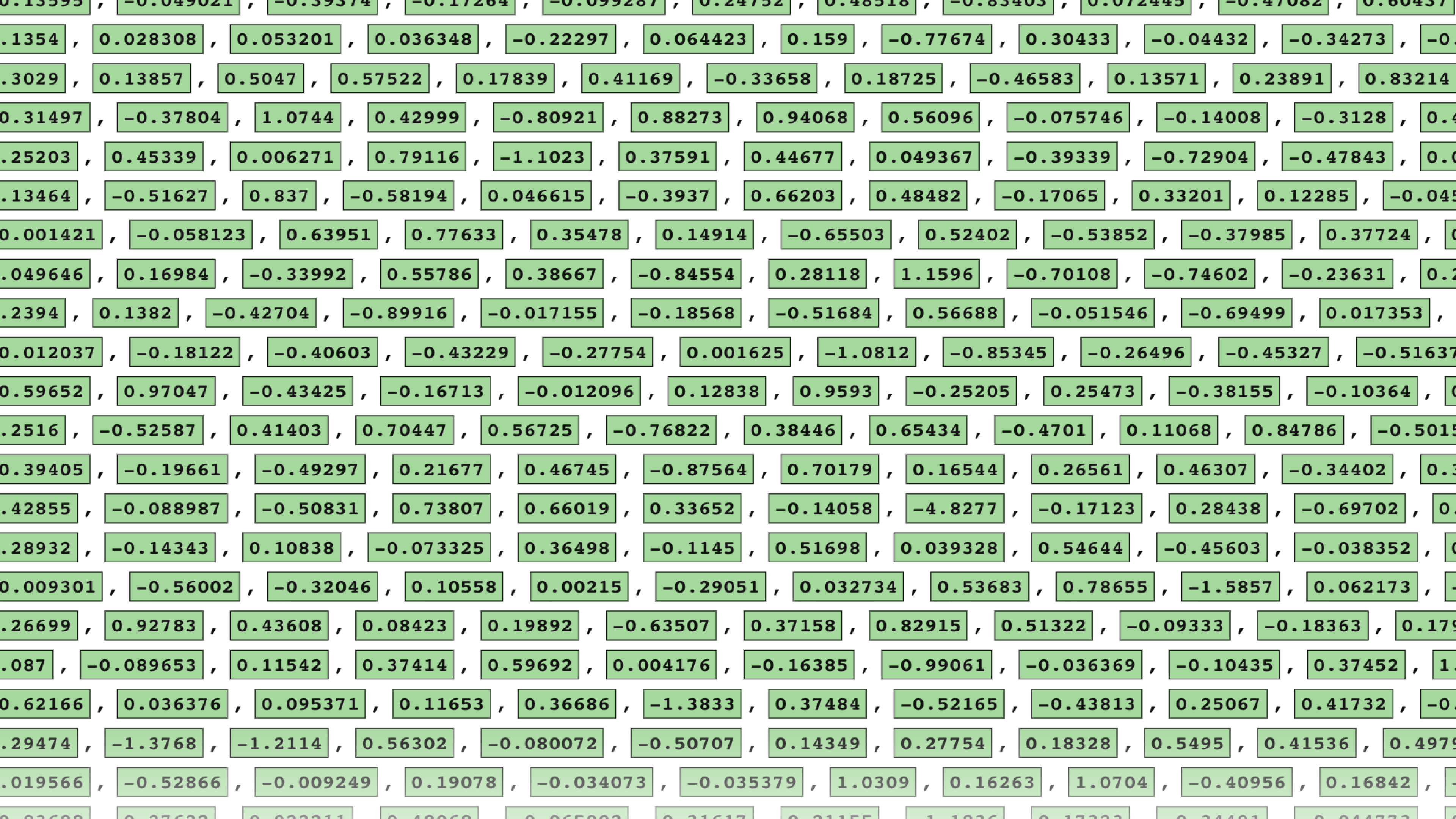
Met een ingewikkeld deep learning model wordt een gigantisch web aan relaties tussen woorden gemaakt. Niet in 2 dimensies, of in 3 dimensies zoals hier, maar in honderden! En deze relaties worden in coordinaten vastgelegd. De coordinaten die je hier ziet zijn een weergave van de relaties van het woord ‘happy’ bijvoorbeeld.

Deze explainer van FT legt het al helemaal goed uit vind ik.
Een woord wordt geanalyseerd in de context van een gigantische hoeveelheid training data. Omliggende woorden worden hierin meegenomen. Langzaam ontstaat een embedding, een weergave van eigenschapen van een woord.
We weten niet echt wat de dimensies inhouden. Maar het kan bijna niet anders dan dat er door langdurige analyse van grote hoeveelheden tekst verbanden worden gelegd die goed overeenkomen met concepten die wij delen als mensen. We zien ook dat gerelateerde woorden gelijkvormige embeddings hebben.
Ieder woord in een zin word steeds opnieuw gewogen ten opzichte van elkaar als er nieuwe informatie bij komt (met een transformer, technisch handigheidje dat je meteen weer kan vergeten). Hierdoor ‘weet’ het model of ‘interest’ in dit geval ‘rente’ of ‘interesse’ betekent. Maar ook dat ‘it’ in deze zin over het bot gaat van de hond.

Als een model getraind is, is het nog niet helemaal klaar voor prime-time. Het kan makkelijk een beetje los slaan, mist soms nog wat ‘gevoel’ voor wanneer je een feitelijk antwoord wil of een poëtische uitwijding. Om de teugels van een getraind model een beetje aan te trekken, wordt een model gefinetuned.
Dit verschilt van trainen doordat het wat specifieker is: als je wil dat een model geneigd is om puntsgewijs antwoord op vragen die feitelijk lijken, kan je met finetunen een hoeveelheid vragen met feitelijke antwoorden als voorbeeld geven. Of als je wil dat een model extra goed wordt in programmeren, kan je als extra’tje een hoeveelheid code voorbeelden geven in verschillende programmeertalen.
Of je voert… schaamteloos je eigen hoofd er aan, zoals heel even heel populair was in het begin van die plaatjesmodellen.

Als je een computer met een goede videokaart huurt, kan je dit in een uurtje ongeveer voor elkaar krijgen. Het model kan je daarna lokaal op je computer draaien als je een nieuwe mac hebt, en dan eeeeh plaatjes draaien maar

Een model wordt ook aangepast met menselijke beoordelingen van responses: Dit heet Reinforcement learning with human feedback (RLHF). Dit wordt ook voor censuur gebruikt. Dit wordt door slecht betaalde gig workers gedaan, vooral in Kenia.

Een taalmodel weet dus niets. Het heeft geen mening, binnenwereld, interne logica. Het kan geen onderscheid maken tussen feiten, het weet niet wat een Bengaalse tijger is. Het is alleen maar een heel ingewikkeld venster op een eindeloos web van relaties.
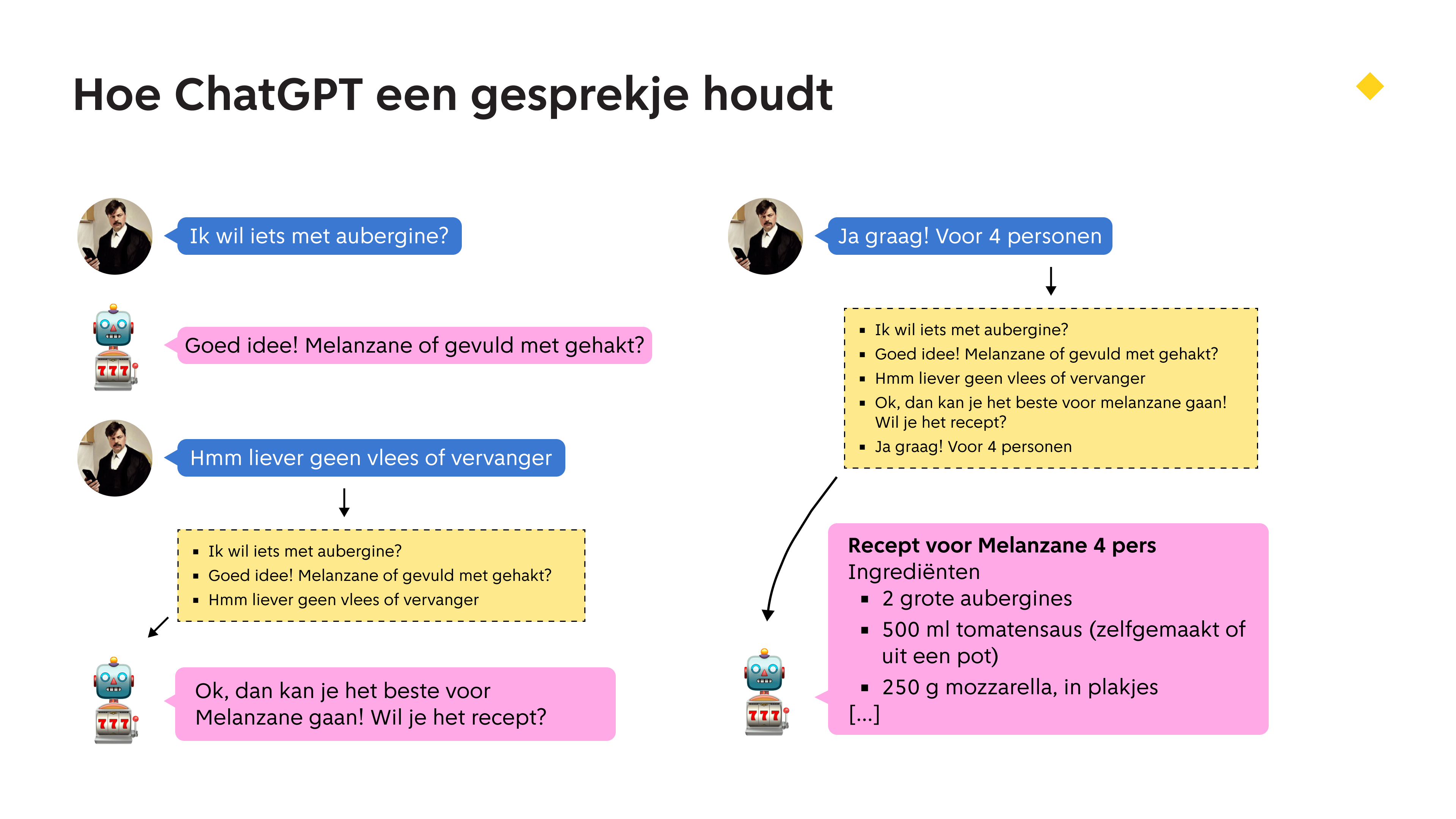
Nog een belangrijk principe om te snappen is dat een taalmodel ook geen geheugen heeft! Dit lijkt alleen maar zo, omdat aan de achterkant het hele gesprek de hele tijd opnieuw afgespeeld wordt.
Laat het met me deze chat uitleggen. Ik wil iets met aubergine, de chat robot antwoord, en ik stel een wedervraag. Wederopmerking :) Maar als ik die opstuur, lepelt de website gewoon het hele gesprekje weer op! En dat gaat dan als een fijn pakketje naar de website waar het chat model draait. Zo vind eigenlijk aan de achterkant een zich steeds herhalend, langer gesprek plaats.
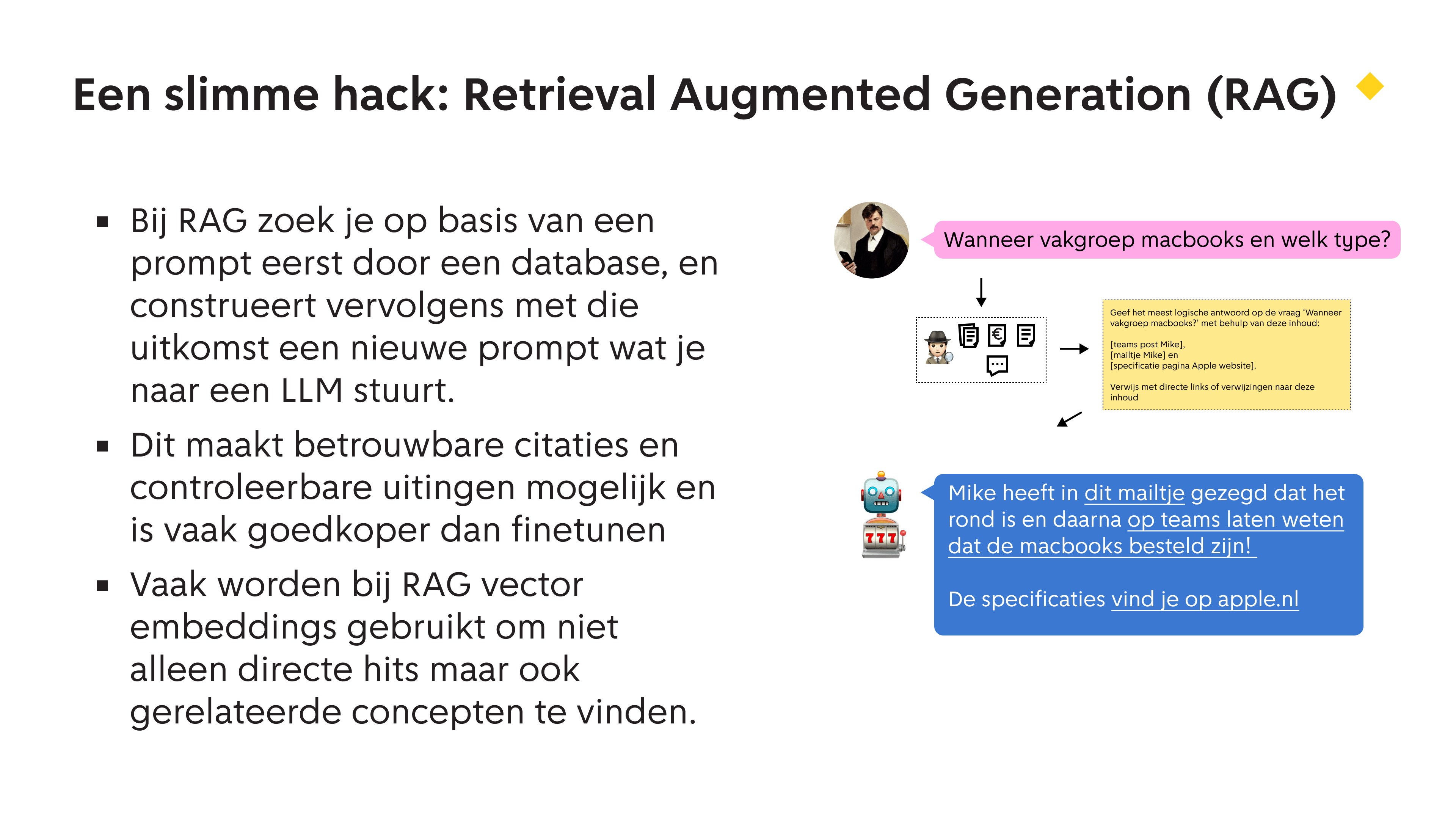
Een manier om een LLM toch met ‘echte’ feiten om te laten gaan, is door zoekmachines te combineren met LLMs. Dat is wat Retrieval Augmented Generation (RAG) feitelijk doet. In dit voorbeeld vraag ik iets over macbooks, en dit stuur ik naar een database die toegang heeft tot mijn mail, teams, en documenten. De database toepassing vind wat relevante informatie, en bakt hier eigenlijk een promptje van. Met een toevoeging als ‘verwijs zo direct mogelijk naar de documentnamen of kanalen die de informatie bevatten, en voeg links toe’. Het taalmodel bakt er vervolgens weer iets appetijtelijks van.
Wat kan je er mee als ontwerper?

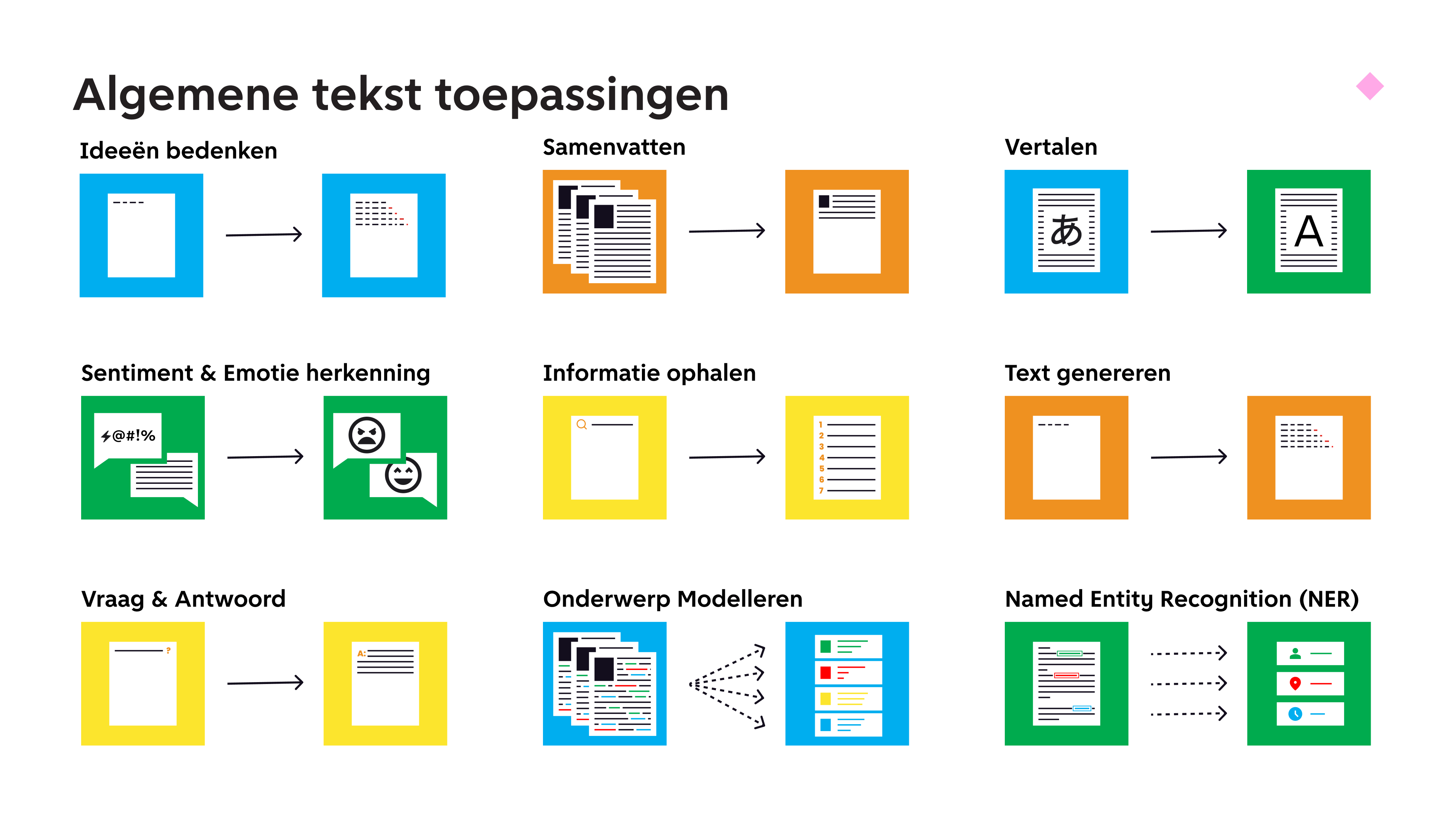
Je kan met een taalmodel heel veel generieke dingen met tekst, zoals je hier kunt zien. Dit kan erg handig zijn in je werk. Je moet wel goed opletten of je gegevens wil en mag delen, maar als je uitspraken van mensen in je onderzoek goed anonimiseert, kan je bijvoorbeeld samenvatten, maar ook goed vragen wat het sentiment van de quotes is, je kan een lopend verhaal maken van quotes, of juist bullet points uit een lang verhaal halen.
Met een audio naar tekst model als Whisper kan je heel goed een transcriptie maken van een opname, en vervolgens met een taalmodel belangrijke punten eruit halen, samenvatten, categoriseren etc. Voor macs is er MacWhisper, een programma die dit allemaal heel makkelijk maakt.

ChatGPT kan dat soort dingen allemaal best goed, en sinds kort is een verbeterde versie van GPT4 ook beschikbaar voor gebruikers zonder betaald account. Het gaat allemaal snel en prettig, als je een beetje goed weet wat je moet vragen. Het kost mij nog best wel wat tijd om er aan te wennen dat ik soms heel goed chatgpt in kan zetten, maar als ik het dan doe is het soms gewoon erg prettig en tijdsbesparend.
Belangrijke dingen waar het goed werkte bij mij was bijvoorbeeld bij het helpen meedenken over aantekeningen van mijn persoonlijke ontwikkeling, bij het maken van voorbeeld-data voor bijvoorbeeld het besluitvormingproject.
Wat ik al eerder gebruikte is github copilot, om te programmeren. Dat laat ik nu even zien.
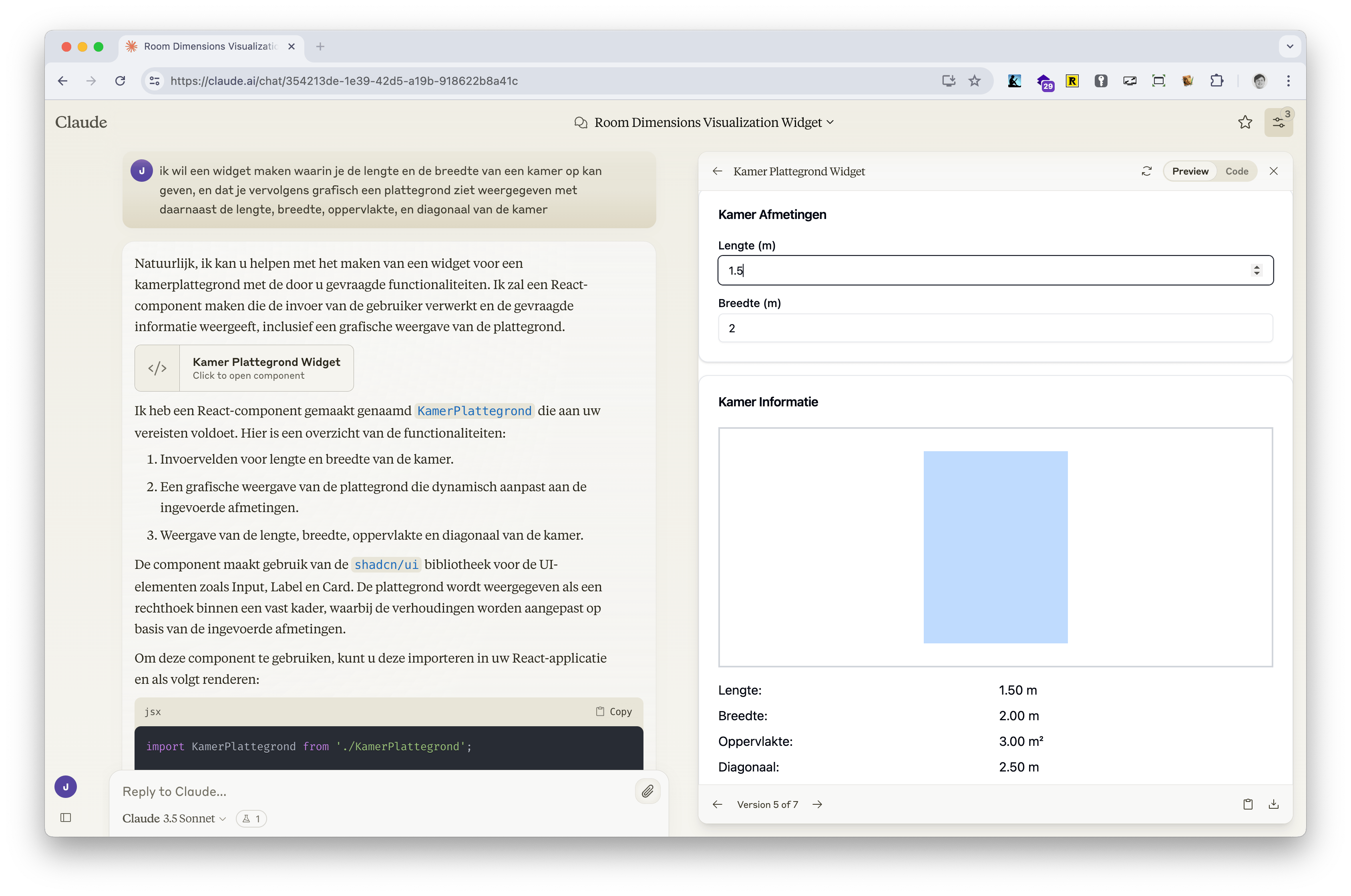
Na deze presentatie ben ik voor privé gebruik overgestapt van ChatGPT naar Claude, een wat menselijker / warmer aanvoelend model, dat heel snel is en ook nog eens een interactief widget laat zien als je het vraagt wat eenvoudigs te programmeren.
TextFX laat zien hoe goed het werkt als je een taalmodel restricties geeft en daarop dingen laat genereren. In dit geval voor rap.
Verder zijn er al de eerste pogingen geweest om ai tools specifiek voor designers te maken. De modellen zijn een beetje oud maar de ideeën zijn wel goed volgens mij: vaste mallen maken zodat je niet helemaal zelf hoeft te bedenken wat je in het chat window zet.
Verder zijn er ook erg leuke dingen die de visie-mogelijkheden goed inzet: hier heb je bijvoorbeeld een tekenprogramma wat ook een interactieve HTML versie kan maken van wat je tekent; en een app voor mensen met een visuele beperking, die met een druk op de knop beschrijft wat er zich afspeelt op de foto die je net genomen hebt.
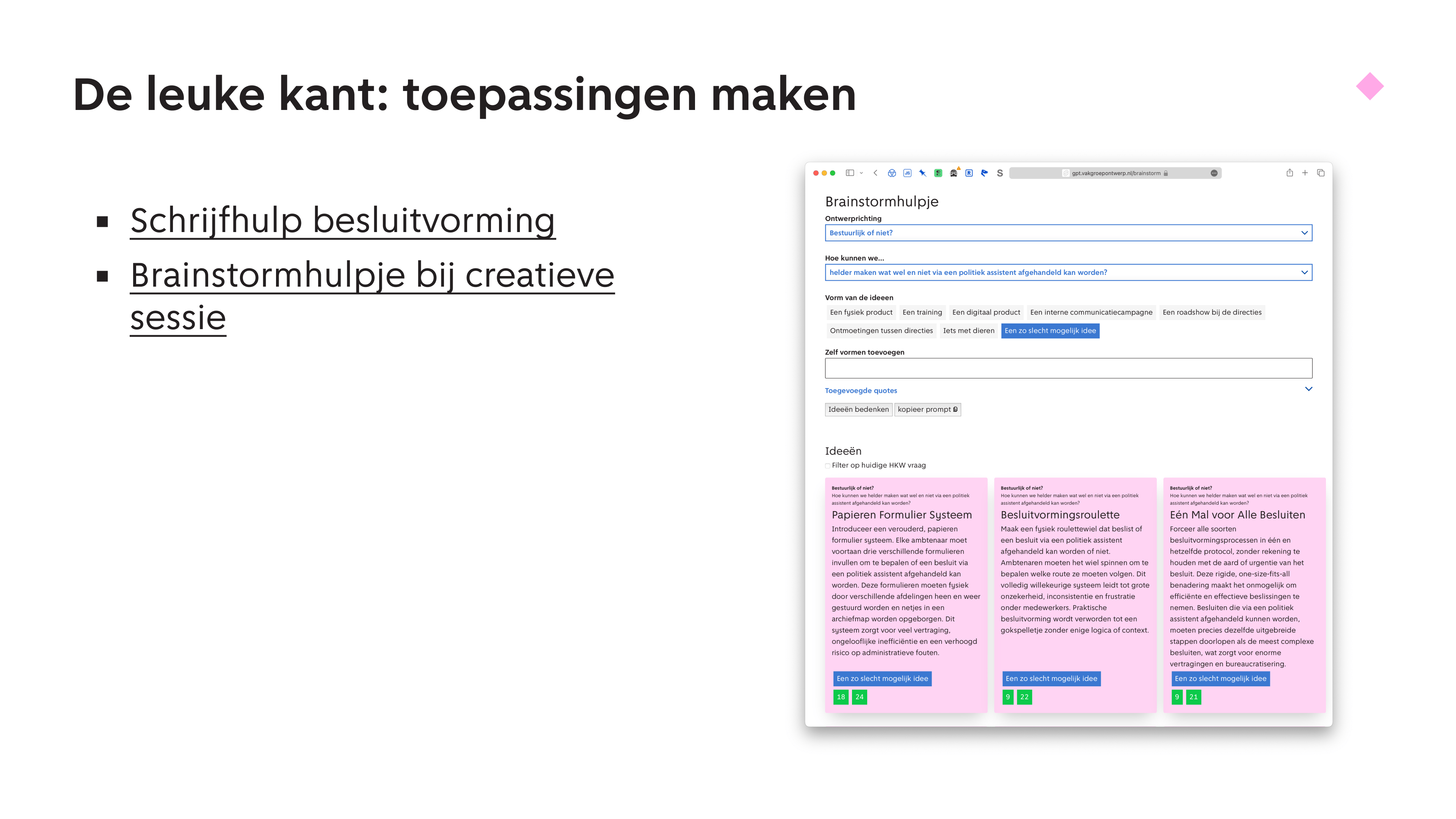
Ik heb uitgewerkt hoe je een taalmodel in kan zetten om iemand op een goede manier te helpen bij het schrijven van besluiten. Ik laat het even zien. Links zie je het besluit. Trouwens, de gemeente verbied het om echte besluiten in wording naar een taalmodel te sturen. Daar ben ik het helemaal mee eens! Dit is slechts een voorstelling van zaken, en zou alleen met een lokaal of anderszins goed afgeschermd taalmodel kunnen.
In ieder geval, aan de achterkant van deze webpagina stuur ik niet alleen de schrijftekst en een uitnodiging om vragen te verzinnen mee, maar ook een waarden-model wat we voor besluitvorming hebben gemaakt, de besluitendriehoek. Of je kan kiezen voor een ander, meer juridisch raamwerk, COBRA.
Deze pagina stelt je steeds een uitdagende vraag op een onderdeel van deze raamwerken. Het prikkelt je om dieper na te denken over zaken als ‘korte- en lange termijn effecten’ en ‘betrokkenheid en inspraak’.
Ik ben groot fan van het gebruik van taalmodellen als sparringspartner en denkhulp. Uitgedaagd worden op je eigen ideeën en tegenvragen kijken is denk ik heel waardevol, het dwingt je om scherper te maken wat je bedoelt en dieper na te denken over je bedoelingen. Dit is heel leuk om met een mens te doen, maar gaat met taalmodellen echt best goed, vooral als je er raamwerken, voorbeeldvragen en andere context in gooit.
Ik heb voor creatieve sessies ook een brainstorm hulpje gemaakt en ingezet. Beetje met wisselend succes, maar ik vond het toch wel leuk. Ik heb in een interface een aantal Hoe Kunnen We vragen gezet, laat mensen een vorm kiezen, en heb ook een aardig aantal quotes uit de interviews in de tool geplaatst.
Al deze context kan de tool meenemen om ideeën te bedenken. Ideeën hebben ook labeltjes naar welke quote ze linken.
De ideeën zijn niet super goed, maar vaak wel een leuk startpunt voor mensen om op voort te borduren. Zo hoeven ze niet blanco te beginnen. Je kan bijvoorbeeld als vorm ook ‘een slecht idee’ kiezen, en daar komen best wel grappige dingen waar je op kan voortborduren.

Nadeel is: je merkt vaak wel dat je een beetje een suffige consultant als sidekick hebt. Je moet goed nadenken en best moeite erin stoppen wil je er echt wat leuks uit krijgen. Als je er vaak mee werkt, krijg je een beetje gevoel voor dingen die met ChatGPT gegenereerd zijn.
Een gerelateerd nadeel is dat er grote hoeveelheden middelmatige content worden gegenereerd met AI om geld mee te verdienen. Deze slop zorgt voor een afbraak van de user experience en betrouwbaarheid van het internet als geheel.

Maar nog belangrijker: je moet er rekening mee houden dat data altijd biased is, en deze modellen zeker ook. Dit kan ook subtiel zijn, en voor jou niet makkelijk waar te nemen. Maar hierover allemaal meer in het volgende stuk.
Design, AI & maatschappij


Deze talk van Dr. Joy Buolamwini op SWSX 2024 heeft veel interessante voorbeelden en punten over bias.

Wieteke heeft jullie als voorbereiding op haar lezing (waar ik helaas niet bij kon zijn) jullie ook gevraagd om een Implicit Association Test (IAT) te doen. Als je dat hebt gedaan, was je zeer waarschijnlijk verbaasd over je eigen mogelijkheden om groepen gelijk te behandelen als je op je system 1 bent aangewezen. Er speelt zich veel onbewust af.
Het AI team (met Anna Kay!) heeft ook een heel interessante analyse van de Chat Amsterdam pilot gepubliceerd op open research met daarin veel inzichten in de bias van modellen, erg de moeite waard om door te nemen.
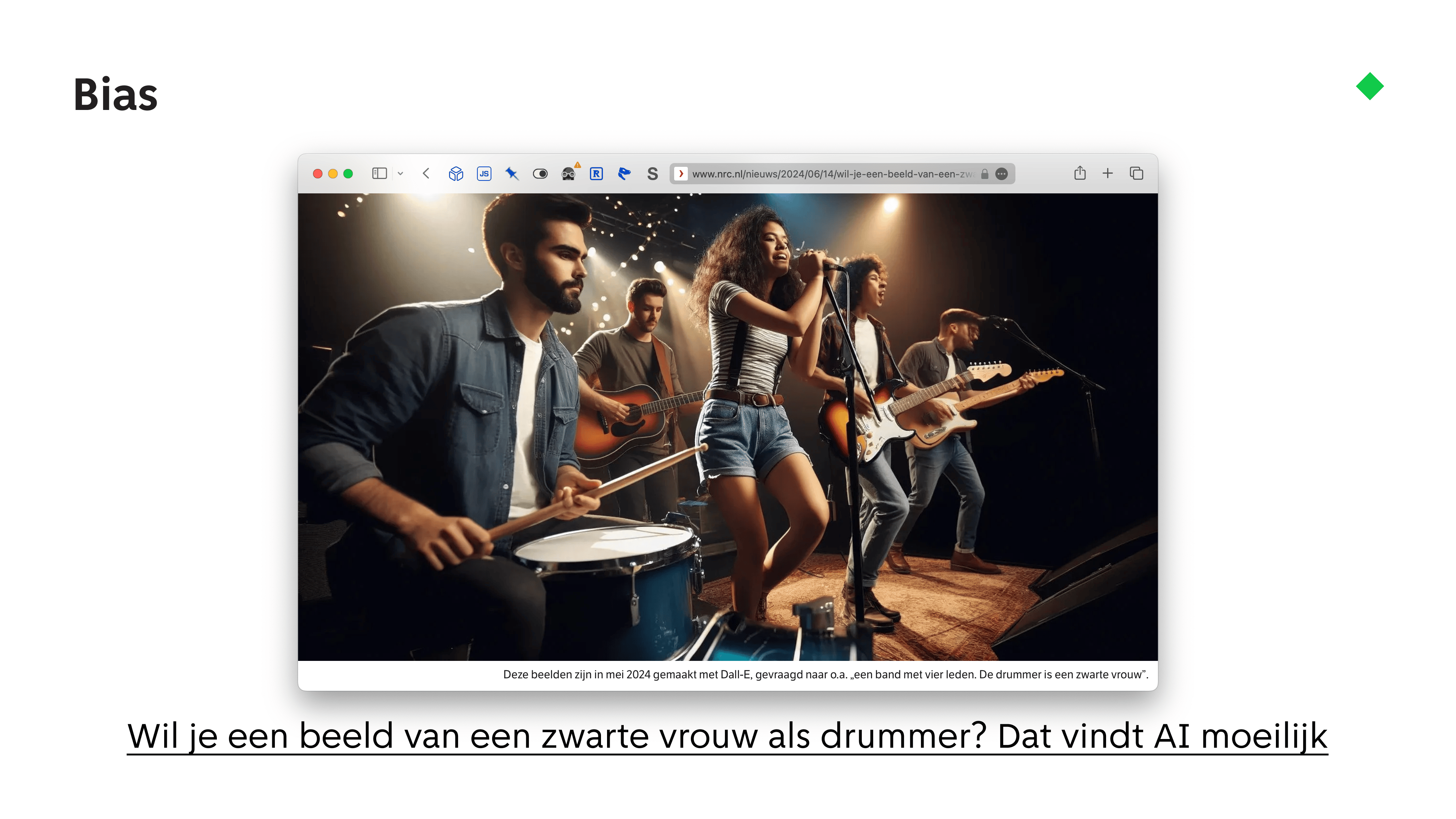
In het NRC van afgelopen weekend staat ook nog een artikel over bias in plaatjesmodellen.

Dan een andere olifant in de kamer: deze modellen zijn behoorlijk verspillend om te trainen, en de grote modellen ook om te gebruiken. Ik vond het moeilijk om hier cijfers bij te vinden die ik in perspectief kon plaatsen, maar het komt er op neer dat het trainen van een model enkele tientallen tot honderden vluchten van Amsterdam naar New York aan co2 kunnen kosten. Het draaien van de modellen is zuiniger, maar een populair project als ChatGPT heeft een grote hoeveelheid videokaarten nodig die de hele tijd staan te loeien.
In verhouding met andere sectoren als landbouw, vervoer of particuliere gamers valt het wel weer mee. Maar als subsector van de toch al vervuilende IT-sector is het energieverbruik ten opzichte van wat je er mee doet wel opvallend hoog. Ik denk dat voor ieder project met een grote generatieve AI component zo goed mogelijk ingeschat moet worden hoeveel co2 dit kost, en hoeveel meer dit is ten opzichte van alternatieven.

Nu het stof een beetje is opgetrokken, valt het nog erg mee met beroepen die echt zijn vervangen door AI. ChatGPT heeft 100 miljoen actieve wekelijkse gebruikers, en dat heeft zeer waarschijnlijk impact op het werk van mensen. Maar op specifieke beroepen, zoals in dit voorbeeld over radiologen, wordt uitgelegd dat AI wel heel goed is in het herkennen van sommige ziektes, in sommige gevallen beter dan mensen, maar dat er een heel automatiseringsstraatje opgetuigd moet worden om dit werkend te krijgen, met veel menselijke controle en aanlevering tussendoor. Het werd veranderd in hoe het georganiseerd wordt, maar het vervangt niet geheel werk.
In ditzelfde artikel wordt ook ingegaan op hoe gig workers worden ingezet om tegen lage betaling, stuksloon, de hele dag op een knop te drukken of een response wel voldoet aan door openai gestelde eisen. Dit is niet bepaald inspirerend werk met ontwikkelingsmogelijkheden. Er wordt toch nog best veel saai werk door mensen gedaan, voor erg weinig geld.
Ik denk dat het gaat om een breder principe, dat ook al speelde bij de opkomst van machine learning modellen: sommige stukken worden geautomatiseerd, maar je houdt een laag over van saai en slecht betaald mensenwerk dat toch gedaan moet worden. Daar zit je dan, met je ‘technologische vooruitgang’.

Gelukkig is er ook een beweging gaande om modellen te maken en de code al dan niet gedeeltelijk vrij te geven. De kleinere modellen kan je op nieuwere macs ook best goed draaien! En het laatste model van Meta, Llama3, heeft bij veel benchmarks vergelijkbare scores met GPT3.5turbo, waar het in het begin allemaal om te doen was. De nieuwste GPT4 is echt veel beter: de dingen die ik hierboven gemaakt zou ik nog steeds daar mee maken, als er geen andere bezwaren zijn.
Maar ik gebruik het wel al regelmatig om stukjes mee te coden, om door te fantaseren op voorbeelden die ik geef, en om dingen samen te vatten. Dat kan op een mac goed met ollama. Ik vind het leuk en bijzonder dat een model van ongeveer 4gigabyte op mijn computer kan leven en dat er zonder internetverbinding dit soort dingen uit kunnen komen. Het is ook erg zuinig! Doet mijn laptop geen centje pijn.

Een moeilijkere vraag, maar die wel steeds in mij op blijft komen, is deze: wordt het er allemaal niet wat fantasielozer en dommer op als mensen voor zoiets belangrijks als je uitdrukken in taal gaan verexcuseren? Ik vind het al zo tragisch dat er zo weinig gelezen wordt door ons als samenleving en zeker ook organisatie. Iedereen ploetert maar aan mooie samenvattingen en rapporten, en als je dan in een meeting vraagt of een beetje test of mensen het gelezen hebben, is het antwoord steeds vaker zonder schaamte ‘nee’.
De oplossing om elkaar beter te begrijpen is dan niet om makkelijker nog meer voor elkaar te produceren om te lezen, of wel? En als je zelf al bedenkt wat het belangrijkste voor iemand om te weten, wil je dan dat jouw boodschap dan altijd door een samenvattingsfilter gaat?
Ook op het internet at large is er nu niet bepaald te weinig content :) Dus bepalen wat je tot je wil nemen en hoe je dingen wil wegen zal alleen maar moeilijker worden, denk ik.

Tegelijk zie ik taalmodellen ook juist als equalizer. Taal is beladen met macht, en bepaald taalgebruik wordt vaak gebruikt om te gatekeepen. Je laat met je manier van praten zien tot welke groep je behoort, hoe slim je denkt te zijn, enzovoorts. ChatGPT maakt dit wel veel eerlijker denk ik. Het kan mensen helpen zich beter uit te drukken, om niet ‘door de mand’ te vallen met taaldingen. Ook voor mensen met bijvoorbeeld dyslexie of een andere beperking die met taal te maken heeft, kan het een zegen zijn. De lees simpel app laat je bijvoorbeeld foto’s van brieven maken en geeft je een simpele, actionable samenvatting.

Je kan me van fanboy zijn betichten, maar ik denk dat de manier waarop Apple AI zegt te gaan integreren erg interessant is. Het is schaamteloos dat ze het Apple Intelligence noemen, en veel van de plaatjes opties zijn een beetje een gimmick, maar ik denk dat het super interessant is dat ze zoveel met lokale modellen kunnen gaan doen, dat ze goed doorhebben dat de grootste waarde zit in het slim gebruiken van je meest persoonlijke data, en dat de privacy focus erg goed is.
Je ziet hier voorbeelden van het snel bundelen van items van een contact persoon over verschillende apps met samenvatting, een inbox waarbij je belangrijkste mails bovenaan staan met een samenvatting die duidelijk aangeven als je ‘iets’ er mee moet, een samenvatting boven een mailtje, etc.
Bedrijven proberen al langer dit soort diepgaande integraties uit, en het klikt nooit echt. Ik hoop heel erg dat dit soort context gevoelige hulpjes het nu wel gaan maken. Voor de chaoten onder ons lijkt het mij een zegen.

Nu dan nog wat eerste gedachten over ethisch ontwerpen met AI. Wij willen hier graag in de komende sessies meer aandacht aan besteden, maar misschien is dit een begin.
Ik denk dat het belangrijk is ok er goed in te worden om af te wegen of AI deel van een oplossing moet zijn. Als je het goed begrijpt, kan je hopelijk inschatten of het echt wat kan brengen. Hier horen ook overwegingen bij over energieverbruik! En je haalt je veel op de hals als je het grondig wil testen. Je moet niet alleen kijken of mensen zich prettig uit kunnen drukken en wegwijs zijn in je product of concept, er is ook kans dat je moet gaan bepalen of ze met de AI intermediary dit ook kunnen. Een extra laag complexiteit.
Verder moet je constant wantrouwend zijn over de feiten en oordelen. Je moet deze ook controleren. Zelfs als je AI het lang en consequent voor je gevoel goed ziet doen (en dit is denk ik niet vaak zo), moet je een mens in de loop hebben. Het gaat namelijk niet alleen over de kwaliteit van de data, maar ook over de betrouwbaarheid en belofte die je hebt met gebruikers, met burgers, dat er door een mens wordt geoordeeld en bekeken.
Ik zie veel kansen voor AI als sparringspartner, denkhulp, maar niet als beoordelaar of op zichzelf staande communicator.
Dit guidebook van Google heeft ook nog interessante afwegingen over het maken van toepassingen waar AI in zit.

Bij besluitvorming heb ik deze voorbeelden gemaakt om aan te tonen wat je volgens mij niet moet doen: AI een eindproduct laten maken waar schijnbaar een afweging heeft plaatsgevonden, of een oordeel wordt geveld. Deze compromis machine produceert best behoorlijke compromissen, maar als het ingewikkeld wordt, valt het niet goed meer uit te leggen.

Deze voordracht-fixer geeft je besluit een rapport cijfer en geeft aan op welke plekken je je besluit moet herschrijven. Misschien super handig, maar niet doen! Het lijkt allemaal logisch maar is niet betrouwbaar, een taalmodel weet niks. Je moet zelf nadenken en stoeien over waarden, anders laat je systemfouten ook altijd bestaan.


- Hoe kunnen we ons het beste voorbereiden op de komst en de brede uitrol van AI-gedreven gebruikers-ervaringen? Wat is een minimaal niveau van domeinkennis dat we nodig hebben, en hoe ziet een ontwerper die gespecialiseerd is in AI eruit?
- Hoe kunnen we goed meedenken met opdrachtgevers over wat AI betekent voor hun vraagstuk? Hoe kunnen we AI ook geïnformeerd afraden?
- Welke aspecten van het werk dat we doen, kunnen beter worden gedaan met de hulp van AI, en hoe kunnen we die ondersteuning versnellen? Omgekeerd, welke onderdelen van het ontwerpproces moeten volgens ons altijd door een mens worden gedaan, en hoe wordt dat behouden?
- Welke bredere ethische vragen rijzen bij AI-ondersteunde en AI-geleverde gebruikservaring, en wat is onze rol in het waarborgen dat Amsterdammers niet worden achtergesteld, gediscrimineerd of zelfs misbruikt?
- Welke toepassingen van generatieve AI kunnen ontwerpers ondersteunen in hun werk?
- Worden de ontwerpers van morgen - die nu op school /uni zitten opgeleid om comfortabel te worden met het ontwerpen met en voor AI? Zo ja, hoe ziet die opleiding eruit?
Er is nog heel veel te vertellen over dit onderwerp, maar gelukkig, aan de andere kant, is dit lange verhaal voor vandaag ook een beetje ten einde. Wij willen jullie als uitsmijter nog wat open vragen meegeven, waar we de komende tijd als groepje over na willen denken.

En tot slot ook nog een vermelding van de gemeentelijke visie op generatieve AI die er aan zit te komen. Er is vanuit deze werkgroep ook al advies over hoe je taalmodellen in je werk mag gebruiken. Omwille van exploratie en dingen uitleggen heb ik bijvoorbeeld wel een API account genomen om wat dingen uit te proberen, wel in overleg overigens.
Mocht je hier verdere vragen over hebben of benieuwd zijn wie je kan helpen bij overwegingen over AI, kan ik je ook zeker aanraden om eens aan te kloppen bij de AI Balie, onderdeel van het AI team van Digitalisering en Innovatie, waar Anna Kay ook in zit! En als AI groepje binnen de vakgroep zijn wij ook altijd beschikbaar. Wij hopen in de workshop sessie of daaromheen ook een samenwerking met het AI team te kunnen doen.
